OpenAI GPT-4.1
OpenAI GPT-4.1 is the latest iteration in the GPT series, specifically designed with developers in mind, offering significant advancements in coding, instruction following, and long-context processing. Available exclusively via API, GPT-4.1 aims to enhance the productivity of developers and power more capable AI agents and applications.
Intended Use
Software development (code generation, debugging, testing, code diffs)
Building AI agents and automating complex workflows
Analyzing and processing large documents and codebases (up to 1M tokens)
Tasks requiring precise instruction following and structured outputs
Multimodal applications involving text and image inputs
Performance
GPT-4.1 introduces a massive 1 million token input context window, a substantial increase over previous models, enabling it to process and reason over extremely large texts or datasets in a single prompt. This significantly improves performance on long-context tasks, including document analysis and multi-hop reasoning.
The model demonstrates notable improvements in coding performance, scoring 54.6% on the SWE-Bench Verified benchmark and showing higher accuracy in generating code diffs compared to its predecessors. It is also specifically tuned for better instruction following, showing improved adherence to complex, multi-step directions and reduced misinterpretations on benchmarks like MultiChallenge and IFEval.
GPT-4.1 maintains multimodal capabilities, accepting text and image inputs. It has shown strong performance on multimodal benchmarks, including those involving visual question answering on charts, diagrams, and even extracting information from videos without subtitles. The model is also highlighted for its 100% accuracy on needle-in-a-haystack retrieval across its entire 1M token context window.
Available in a family of models including GPT-4.1, GPT-4.1 mini (optimized for balance of performance and cost), and GPT-4.1 nano (optimized for speed and cost), GPT-4.1 offers flexibility for various developer needs and aims for improved cost-efficiency compared to earlier models like GPT-4o for many use cases.
Limitations
API-only availability: Unlike some previous GPT models, GPT-4.1 is currently available exclusively through the API and is not directly accessible in the ChatGPT consumer interface.
Rate limits: While offering a large context window, practical usage for extremely high-volume or continuous long-context tasks can be impacted by API rate limits, which vary by usage tier.
Reasoning specialization: While demonstrating improved reasoning, GPT-4.1 is not primarily positioned as a dedicated reasoning model in the same category as some models specifically optimized for deep, step-by-step logical deduction.
Potential for "laziness" in smaller variants: Some initial user observations have suggested that the smallest variant, GPT-4.1 nano, can occasionally exhibit a tendency for shorter or less detailed responses, potentially requiring more specific prompting.
Multimodal output: While accepting text and image inputs, the primary output modality is text; it does not generate images directly like some other multimodal models.
Citation
Google Gemini 2.0 Pro
Gemini 2.0 Pro is the strongest model among the family of Gemini models for coding and world knowledge, and it features a 2M long context window. Gemini 2.0 Pro is available as an experimental model in Vertex AI and is an upgrade path for 1.5 Pro users who want better quality, or who are particularly invested in long context and code.
Intended Use
Multimodal input
Text output
Prompt optimizers
Controlled generation
Function calling (excluding compositional function calling)
Grounding with Google Search
Code execution
Count token
Performance
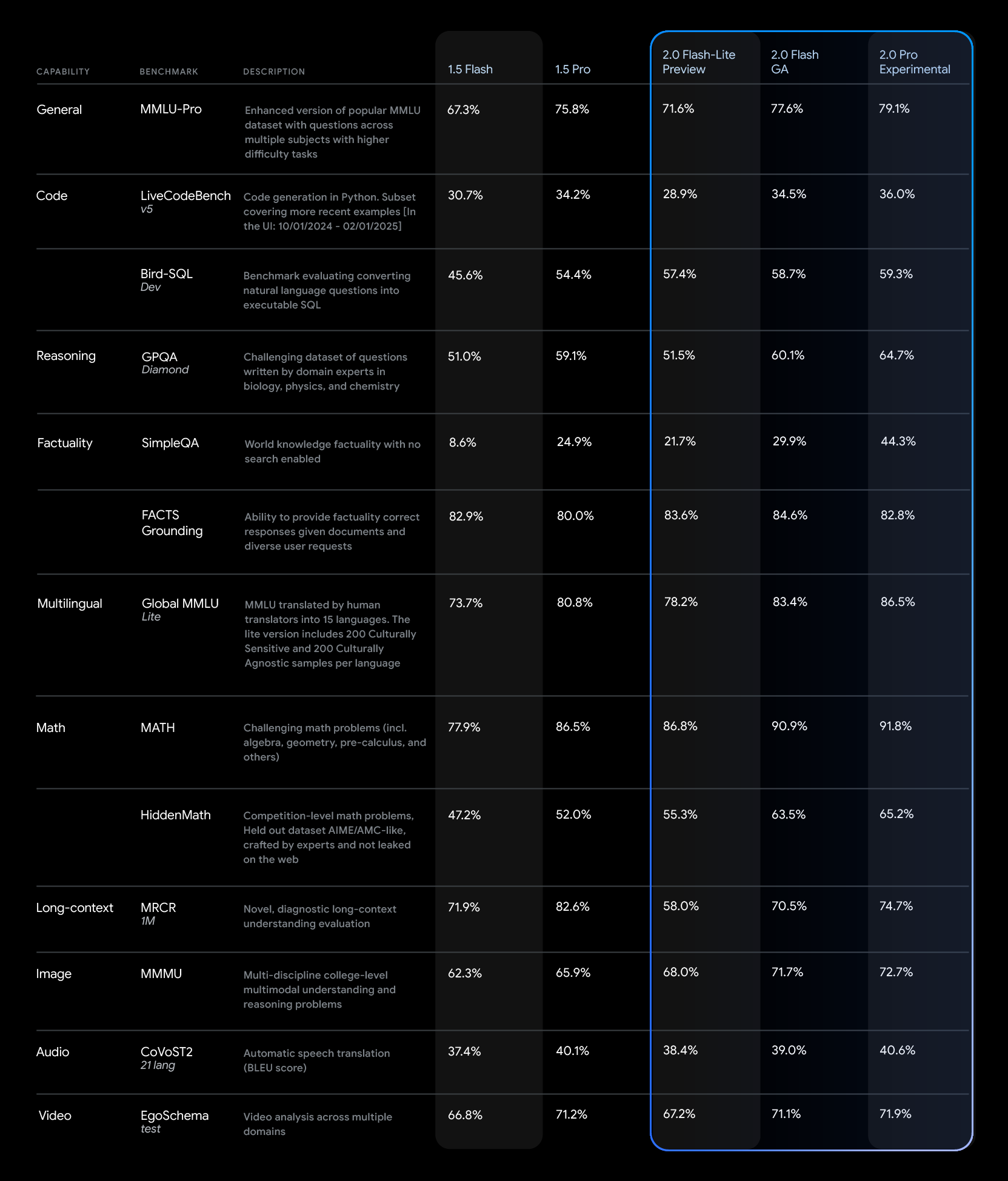
Google Gemini 2.0 Pro boasts the strongest coding performance and superior ability to handle complex prompts, demonstrating better understanding and reasoning of world knowledge than any previous model.
It features the largest context window of 2 million tokens, enabling comprehensive analysis and understanding of large amounts of information. Additionally, it can call external tools like Google Search and execute code, enhancing its utility for a wide range of tasks, including coding and knowledge analysis.
Limitations
Context: Gemini 2.0 Pro may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As Gemini 2.0 Pro is trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Gemini 2.0 Pro may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Gemini 2.0 Pro can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Gemini 2.0 Pro might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of Gemini 2.0 Pro's output are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://cloud.google.com/vertex-ai/generative-ai/docs/gemini-v2#2.0-pro
Claude 3.5 Sonnet
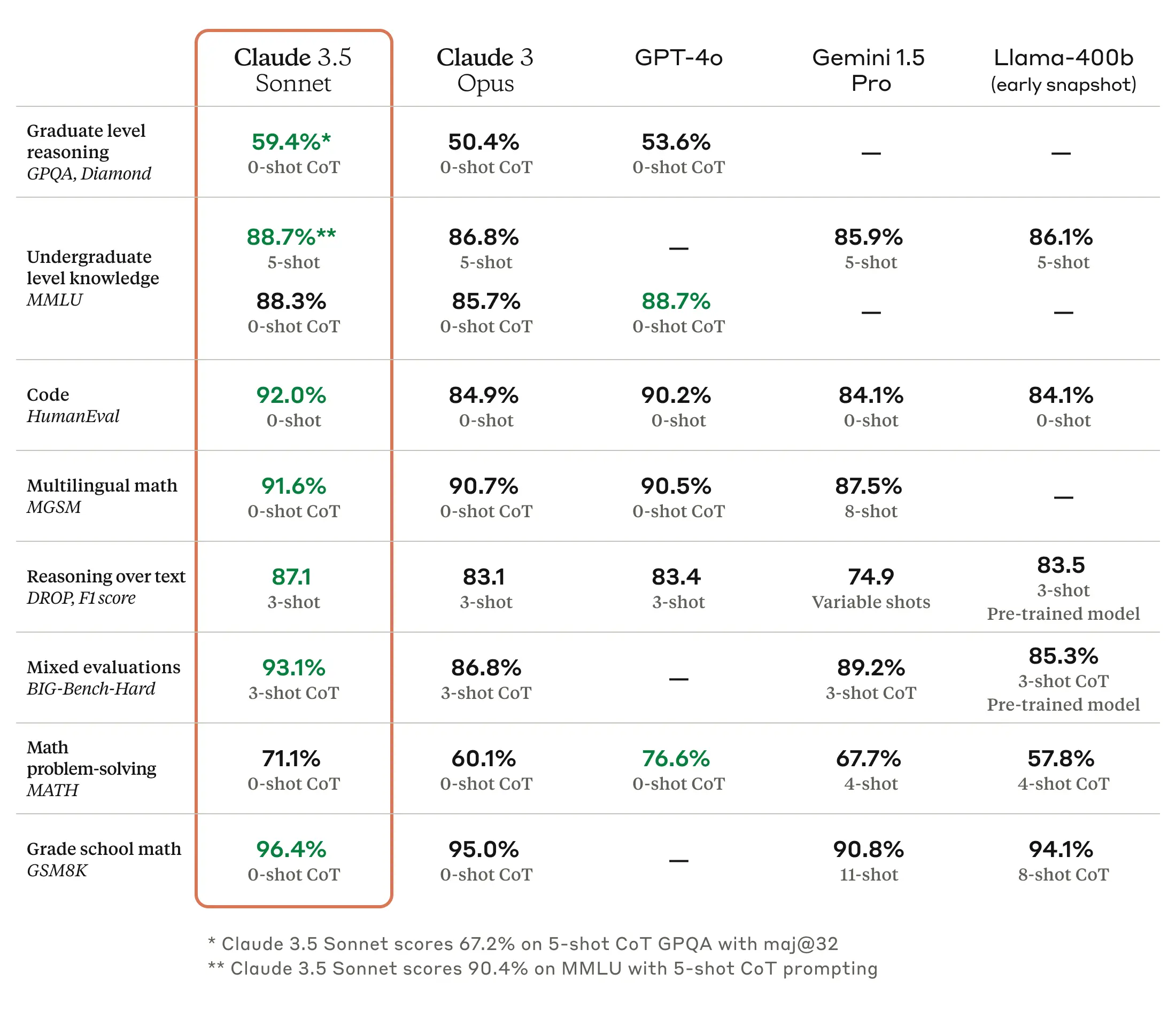
Claude 3.5 Sonnet sets new industry benchmarks for graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (HumanEval). It shows marked improvement in grasping nuance, humor, and complex instructions, and is exceptional at writing high-quality content with a natural, relatable tone. Claude 3.5 Sonnet operates at twice the speed of Claude 3 Opus. This performance boost, combined with cost-effective pricing, makes Claude 3.5 Sonnet ideal for complex tasks such as context-sensitive customer support and orchestrating multi-step workflows.
Intended Use
Task automation: plan and execute complex actions across APIs and databases, interactive coding
R&D: research review, brainstorming and hypothesis generation, drug discovery
Strategy: advanced analysis of charts & graphs, financials and market trends, forecasting
Performance
Advanced Coding ability: In an internal evaluation by Anthropic, Claude 3.5 Sonnet solved 64% of problems, outperforming Claude 3 Opus which solved 38%.
Multilingual Capabilities: Claude 3.5 Sonnet offers improved fluency in non-English languages such as Spanish and Japanese, enabling use cases like translation services and global content creation.
Vision and Image Processing: This model can process and analyze visual input, extracting insights from documents, processing web UI, generating image catalog metadata, and more.
Steerability and Ease of Use: Claude 3.5 Sonnet is designed to be easy to steer and better at following directions, giving you more control over model behavior and more predictable, higher-quality outputs.
Limitations
Here are some of the limitations we are aware of:
Medical images: Claude 3.5 is not suitable for interpreting specialized medical images like CT scans and shouldn't be used for medical advice.
Non-English: Claude 3.5 may not perform optimally when handling images with text of non-Latin alphabets, such as Japanese or Korean.
Big text: Users should enlarge text within the image to improve readability for Claude 3.5, but avoid cropping important details.
Rotation: Claude 3.5 may misinterpret rotated / upside-down text or images.
Visual elements: Claude 3.5 may struggle to understand graphs or text where colors or styles like solid, dashed, or dotted lines vary.
Spatial reasoning: Claude 3.5 struggles with tasks requiring precise spatial localization, such as identifying chess positions.
Hallucinations: the model can provide factually inaccurate information.
Image shape: Claude 3.5 struggles with panoramic and fisheye images.
Metadata and resizing: Claude 3.5 doesn't process original file names or metadata, and images are resized before analysis, affecting their original dimensions.
Counting: Claude 3.5 may give approximate counts for objects in images.
CAPTCHAS: For safety reasons, Claude 3.5 has a system to block the submission of CAPTCHAs.
Citation
Bring your own model
Register your own custom models in Labelbox to pre-label or enrich datasetsLlama 4 Maverick
Meta Llama 4 Maverick is a cutting-edge, natively multimodal AI model from Meta, part of the new Llama 4 family. Built with a Mixture-of-Experts (MoE) architecture, Maverick is designed for advanced text and image understanding, aiming to provide industry-leading performance for a variety of applications at competitive costs.
Intended Use
Developing multimodal assistant applications (image recognition, visual reasoning, captioning, Q&A about images)
Code generation and technical tasks
General-purpose text generation and chat
Enterprise applications requiring multimodal data processing
Research and development in AI
Performance
Llama 4 Maverick features a Mixture-of-Experts architecture with 17 billion active parameters (from a total of 400 billion), contributing to its efficiency and performance. It is natively multimodal, incorporating early fusion of text and image data during training, which allows for seamless understanding and reasoning across modalities. The model supports a context window of up to 1 million tokens, enabling processing of extensive documents and complex inputs.
Benchmark results highlight Maverick's strong capabilities, particularly in multimodal understanding. It has achieved scores of 59.6 on MMLU Pro, 90.0 on ChartQA, 94.4 on DocVQA, 73.4 on MMMU, and 73.7 on MathVista. In coding, it scored 43.4 on LiveCodeBench (specific timeframe). On the LMSYS Chatbot Arena, an experimental chat version of Maverick reportedly achieved an ELO score of 1417, placing it competitively among top models.
Maverick is designed for efficient deployment, capable of running on a single H100 DGX host, with options for distributed inference for larger-scale needs. Its MoE architecture helps balance powerful performance with inference efficiency.
Limitations
EU restriction on vision: Due to regulatory considerations, the use of the vision capabilities for individuals domiciled in, or companies with a principal place of business in, the European Union is not granted under the Llama 4 Community License.
Dedicated reasoning focus: While capable of reasoning, Llama 4 Maverick is not specifically positioned as a dedicated reasoning model in the same vein as some models optimized solely for complex, multi-step logical deduction.
Long context consistency: Despite a large context window, some initial testing has suggested potential for inconsistent performance or degraded results with exceptionally long prompts.
Image input testing: The model has been primarily tested for image understanding with up to 5 input images; performance with a larger number of images may vary, and developers are advised to perform additional testing for such use cases.
Benchmark interpretation: As with many frontier models, there have been discussions regarding the interpretation and representativeness of benchmark scores compared to real-world performance across all possible tasks.
Memory intensity: The Mixture-of-Experts architecture, while efficient for inference, means the full model still requires significant memory to load.
Citation
Information gathered from Meta's official Llama website, announcements, technical documentation (including the Llama 4 Community License), and third-party analyses and benchmark reports.
Google Gemini 2.5 Pro
Gemini 2.5 is a thinking model, designed to tackle increasingly complex problems. Gemini 2.5 Pro Experimental, leads common benchmarks by meaningful margins and showcases strong reasoning and code capabilities. Gemini 2.5 models are thinking models, capable of reasoning through their thoughts before responding, resulting in enhanced performance and improved accuracy.
Intended Use
Multimodal input
Text output
Prompt optimizers
Controlled generation
Function calling (excluding compositional function calling)
Grounding with Google Search
Code execution
Count token
Performance
Google’s latest AI model, Gemini 2.5 Pro, represents a major leap in AI performance and reasoning capabilities. Positioned as the most advanced iteration in the Gemini lineup, this experimental release of 2.5 Pro is now the top performer on the LMArena leaderboard, surpassing other models by a notable margin in human preference evaluations.
Gemini 2.5 builds on Google’s prior efforts to enhance reasoning in AI, incorporating advanced techniques like reinforcement learning and chain-of-thought prompting. This version introduces a significantly upgraded base model paired with improved post-training, resulting in better contextual understanding and more accurate decision-making. The model is designed as a “thinking model,” capable of deeply analyzing information before responding — a capability now embedded across all future Gemini models.
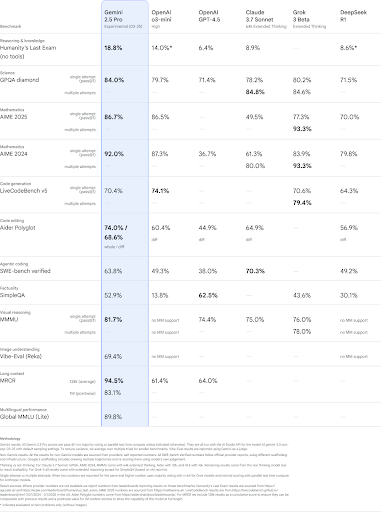
The reasoning performance of 2.5 Pro stands out across key benchmarks such as GPQA and AIME 2025, even without cost-increasing test-time techniques. It also achieved a state-of-the-art 18.8% score on “Humanity’s Last Exam,” a benchmark crafted by experts to evaluate deep reasoning across disciplines.
In terms of coding, Gemini 2.5 Pro significantly outperforms its predecessors. It excels in creating complex, visually rich web apps and agentic applications. On SWE-Bench Verified, a standard for evaluating coding agents, the model scored an impressive 63.8% using a custom setup.
Additional features include a 1 million token context window, with plans to extend to 2 million, enabling the model to manage vast datasets and multimodal inputs — including text, images, audio, video, and code repositories.
Limitations
Context: Google Gemini 2.5 Pro may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As it is trained on a large corpus of internet text, Google Gemini 2.5 Pro may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Google Gemini 2.5 Pro may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Google Gemini 2.5 Pro can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Google Gemini 2.5 Pro might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the model’s output are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://cloud.google.com/vertex-ai/generative-ai/docs/gemini-v2#2.5-pro
Grok 3
Grok 3, developed by xAI, is positioned as a highly advanced AI model engineered for complex problem-solving and real-time information processing. Leveraging a massive computational infrastructure, Grok 3 introduces innovative features like "Think mode" for detailed reasoning and "DeepSearch" for integrating current web data, aiming to push the boundaries of AI capabilities across various domains.
Intended Use
Real-time data analysis and research
Code generation and debugging
Educational assistance and STEM learning
Business process automation
Generating both conversational and detailed responses
Performance
Powered by the Colossus supercomputer with over 200,000 NVIDIA H100 GPUs, Grok 3 represents a significant leap in computational power, reportedly 10-15x more powerful than its predecessor. This enables enhanced speed and efficiency in processing complex queries. Grok 3 has demonstrated impressive results across key benchmarks.
It achieved a 93.3% score on the AIME 2025 mathematical assessment and 84.6% on graduate-level expert reasoning tasks (GPQA). In coding challenges, it scored 79.4% on LiveCodeBench. Internal benchmarks from xAI also suggest Grok 3 outperforms several leading models, including Gemini 2.5 Pro, GPT-4o, and Claude 3.5 Sonnet, in specific reasoning, math, and coding tasks.
A notable feature is "Think mode," which allows Grok 3 to break down problems and show its step-by-step reasoning process, similar to human structured thinking. "Big Brain mode" allocates additional computational resources for demanding tasks, delivering higher accuracy and deeper insights. The "DeepSearch" capability allows the model to pull and synthesize real-time information from the web, addressing the limitation of relying solely on static training data.
While benchmark performance is strong, real-world performance comparisons show varied results, with Grok 3 excelling in logic-heavy tasks and real-time data integration.
Limitations
Content coherency: Grok 3 may struggle with maintaining full coherency in generating very long-form content (e.g., beyond 5-10 pages).
Real-time data reliability: While "DeepSearch" provides access to real-time data from sources like X and the web, there is a potential risk of generating unverified or biased information depending on the source quality.
Varied real-world performance: Despite strong benchmark scores, some early real-world tests indicate that Grok 3 may not consistently outperform all rival models in every specific task.
Creativity nuances: The model's creative writing abilities may be perceived as more functional than nuanced compared to models specifically fine-tuned for highly creative tasks.
Resource intensity: Utilizing advanced reasoning modes like "Big Brain" requires significant computational resources, which could impact response times and cost efficiency depending on the application.
Citation
Information gathered from various public sources, including xAI announcements, technical reviews, and public benchmark analyses.
OpenAI o4-mini
OpenAI o4-mini is a recent addition to OpenAI's 'o' series of models, designed to provide fast, cost-efficient, and capable reasoning for a wide range of tasks. It balances performance with efficiency, making advanced AI reasoning more accessible for various applications, including those requiring high throughput.
Intended Use
Fast technical tasks (data extraction, summarization of technical content)
Coding assistance (fixing issues, generating code)
Automating workflows (intelligent email triage, data categorization)
Processing and reasoning about multimodal inputs (text and images)
Applications where speed and cost-efficiency are key
Performance
OpenAI o4-mini is optimized for speed and affordability while still demonstrating strong reasoning capabilities. It features a substantial 200,000-token context window, allowing it to handle lengthy inputs and maintain context over extended interactions. The model supports up to 100,000 output tokens.
Despite being a smaller model, o4-mini shows competitive performance on several benchmarks, particularly in STEM and multimodal reasoning tasks. It has achieved scores such as 93.4% on AIME 2024 and 81.4% on GPQA (without tools). In coding, it demonstrates effective performance on benchmarks like SWE-Bench.
A key capability of o4-mini is its integration with OpenAI's suite of tools, including web Browse, Python code execution, and image analysis. The model is trained to intelligently decide when and how to use these tools to solve complex problems and provide detailed, well-structured responses, even incorporating visual information into its reasoning process. This makes it adept at tasks that require combining information from multiple sources or modalities.
Compared to larger models like OpenAI o3, o4-mini generally offers faster response times and significantly lower costs per token, making it a strong candidate for high-volume or latency-sensitive applications.
Limitations
Usage limits: Access to o4-mini on ChatGPT is subject to usage limits depending on the subscription tier (Free, Plus, Team, Enterprise/Edu).
Fine-tuning: As of the latest information, fine-tuning capabilities are not yet available for o4-mini.
Reasoning depth: While strong for its size, o4-mini may not offer the same depth of reasoning as larger, more powerful models like o3 for the most complex, multi-step problems.
Benchmark vs. real-world: As with any model, performance on specific benchmarks may not always perfectly reflect performance on all real-world, highly-nuanced tasks.
Citation
Information gathered from OpenAI's official announcements, documentation, and third-party analyses of model capabilities and benchmarks.
Bring your own model
Register your own custom models in Labelbox to pre-label or enrich datasetsOpen AI Whisper
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual data, offering improved robustness to accents, noise, and technical language. It transcribes and translates multiple languages into English.
Intended Use
Whisper is useful as an ASR solution, especially for English speech recognition.
The models are primarily trained and evaluated on ASR and speech translation to English.
They show strong ASR results in about 10 languages.
They may exhibit additional capabilities if fine-tuned for tasks like voice activity detection, speaker classification, or speaker diarization.
Performance
Speech recognition and translation accuracy is near state-of-the-art.
Performance varies across languages, with lower accuracy on low-resource or low-discoverability languages.
Whisper shows varying performance on different accents and dialects of languages.
Limitations
Whisper is trained in a weakly supervised manner using large-scale noisy data, leading to potential hallucinations.
Hallucinations occur as the models combine predicting the next word and transcribing audio.
The sequence-to-sequence architecture may generate repetitive text, which can be partially mitigated by beam search and temperature scheduling.
These issues may be more pronounced in lower-resource and/or lower-discoverability languages.
Higher word error rates may occur across speakers of different genders, races, ages, or other demographics.
Citation
https://openai.com/index/whisper/
Open AI o3 mini
OpenAI o3-mini is a powerful and fast model that advances the boundaries of what small models can achieve. It delivers, exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of OpenAI o1-mini.
Intended Use
OpenAI o3-mini is designed to be used for tasks that require fast and efficient reasoning, particularly in technical domains like science, math, and coding. It’s optimized for STEM (Science, Technology, Engineering, and Mathematics) problem-solving, offering precise answers with improved speed compared to previous models.
Developers can use it for applications involving function calling, structured outputs, and other technical features. It’s particularly useful in contexts where both speed and accuracy are essential, such as coding, logical problem-solving, and complex technical inquiries.
Performance
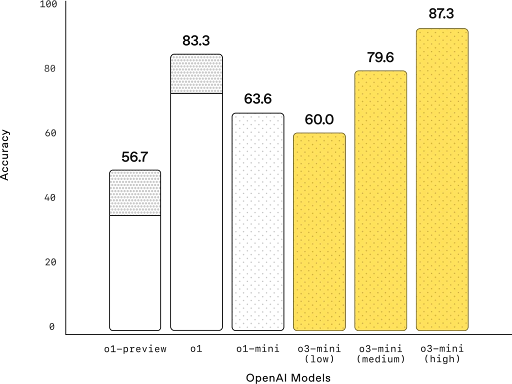
OpenAI o3-mini performs exceptionally well in STEM tasks, particularly in science, math, and coding, with improvements in both speed and accuracy compared to its predecessor, o1-mini. It delivers faster responses, with an average response time 24% quicker than o1-mini (7.7 seconds vs. 10.16 seconds).
In terms of accuracy, it produces clearer, more accurate answers, with 39% fewer major errors on complex real-world questions. Expert testers preferred its responses 56% of the time over o1-mini. It also matches o1-mini’s performance in challenging reasoning evaluations, including AIME and GPQA, especially when using medium reasoning effort.
Limitations
No Vision Capabilities: Unlike some other models, o3-mini does not support visual reasoning tasks, so it's not suitable for image-related tasks.
Complexity in High-Intelligence Tasks: While o3-mini performs well in most STEM tasks, for extremely complex reasoning, it may still lag behind larger models.
Accuracy in Specific Domains: While o3-mini excels in technical domains, it might not always match the performance of specialized models in certain niche areas, particularly those outside of STEM.
Potential Trade-Off Between Speed and Accuracy: While users can adjust reasoning effort for a balance, higher reasoning efforts may lead to slightly longer response times.
Limited Fine-Tuning: Though optimized for general STEM tasks, fine-tuning for specific use cases might be necessary to achieve optimal results in more specialized areas.
Citation
https://openai.com/index/openai-o3-mini/
Claude 3.7 Sonnet
Claude 3.7 Sonnet, by Anthropic, can produce near-instant responses or extended, step-by-step thinking. Claude 3.7 Sonnet shows particularly strong improvements in coding and front-end web development.
Intended Use
Claude 3.7 Sonnet is designed to enhance real-world tasks by offering a blend of fast responses and deep reasoning, particularly in coding, web development, problem-solving, and instruction-following.
Optimized for real-world applications rather than competitive math or computer science problems.
Useful in business environments requiring a balance of speed and accuracy.
Ideal for tasks like bug fixing, feature development, and large-scale refactoring.
Coding Capabilities:
Strong in handling complex codebases, planning code changes, and full-stack updates.
Introduces Claude Code, an agentic coding tool that can edit files, write and run tests, and manage code repositories like GitHub.
Claude Code significantly reduces development time by automating tasks that would typically take 45+ minutes manually.
Performance
Claude Sonnet 3.7 combines the capabilities of a language model (LLM) with advanced reasoning, allowing users to choose between standard mode for quick responses and extended thinking mode for deeper reflection before answering. In extended thinking mode, Claude self-reflects, improving performance in tasks like math, physics, coding, and following instructions. Users can also control the thinking time via the API, adjusting the token budget to balance speed and answer quality.
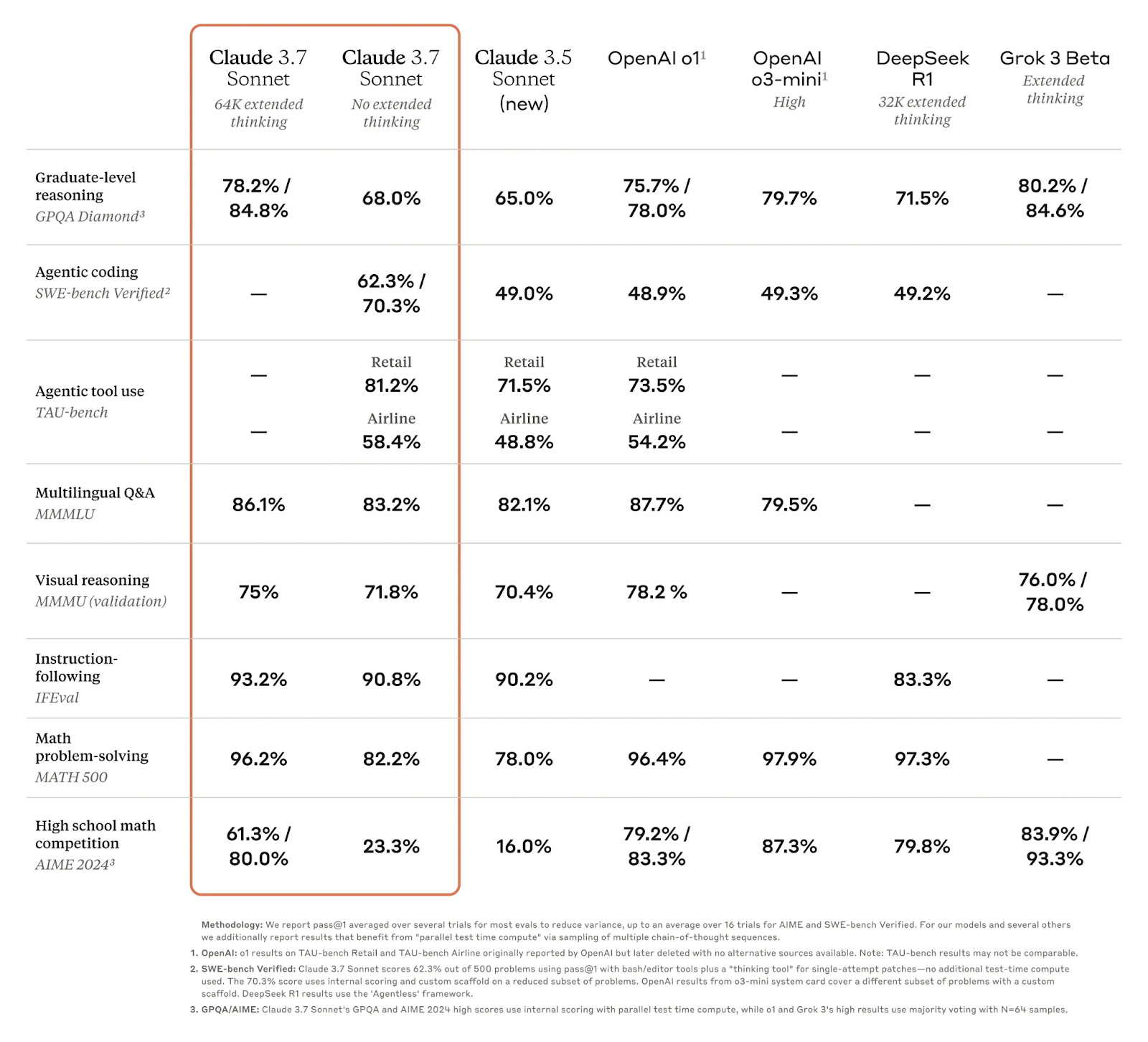
Early testing demonstrated Claude’s superiority in coding, with significant improvements in handling complex codebases, advanced tool usage, and planning code changes. It also excels at full-stack updates and producing production-ready code with high precision, as seen in use cases with platforms like Vercel, Replit, and Canva. Claude's performance is particularly strong in developing sophisticated web apps, dashboards, and reducing errors. This makes it a top choice for developers working on real-world coding tasks.
Limitations
Context: Claude 3.7 Sonnet may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As Claude 3.7 Sonnet trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Claude 3.7 Sonnet may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Claude 3.7 Sonnet can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Claude 3.7 Sonnet might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the output of Claude 3.7 Sonnet are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://www.anthropic.com/news/claude-3-7-sonnet
Amazon Nova Pro
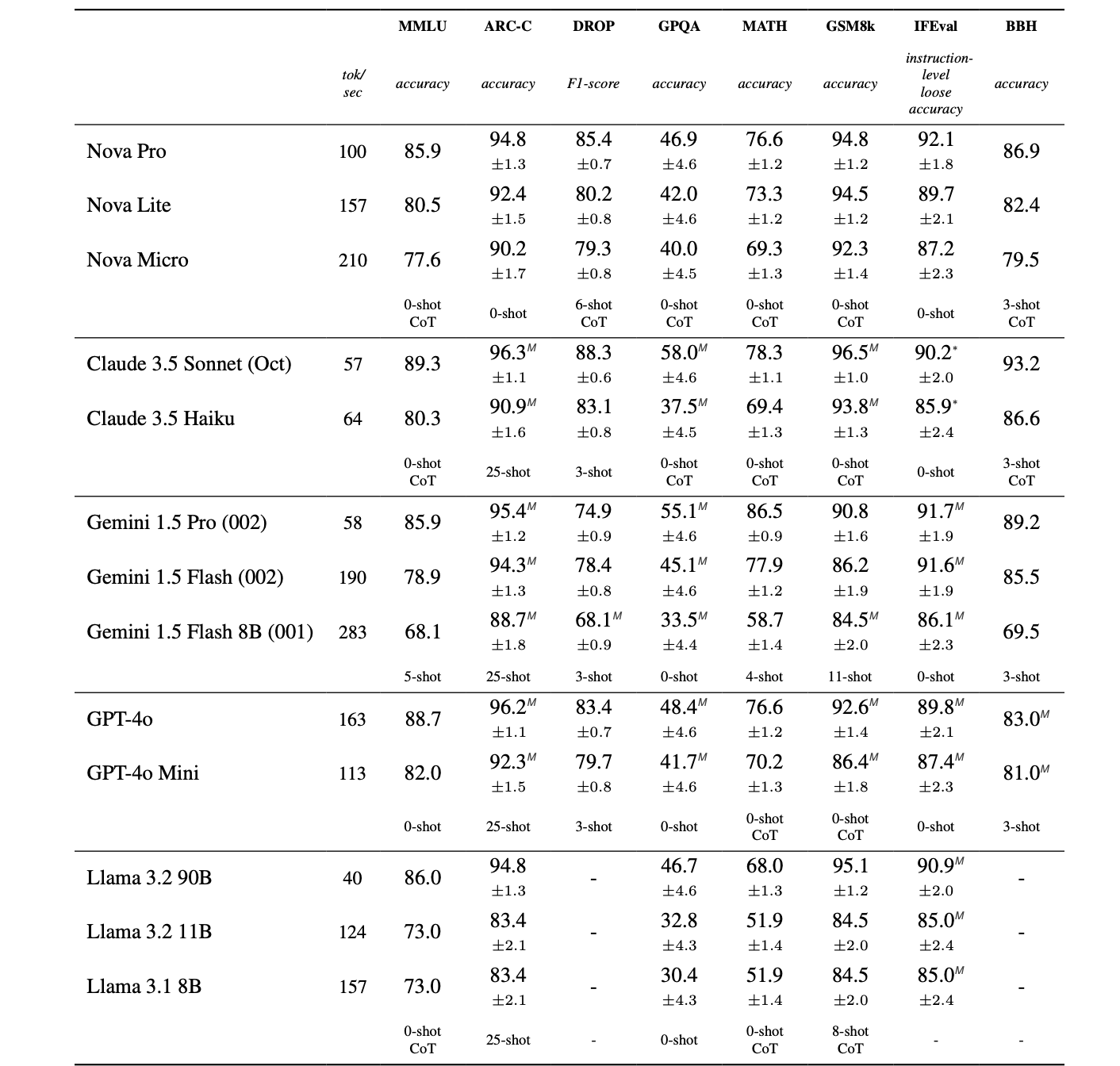
Amazon Nova Pro is a highly capable multimodal model that combines accuracy, speed, and cost for a wide range of tasks.
The capabilities of Amazon Nova Pro, coupled with its focus on high speeds and cost efficiency, makes it a compelling model for almost any task, including video summarization, Q&A, mathematical reasoning, software development, and AI agents that can execute multistep workflows.
In addition to state-of-the-art accuracy on text and visual intelligence benchmarks, Amazon Nova Pro excels at instruction following and agentic workflows as measured by Comprehensive RAG Benchmark (CRAG), the Berkeley Function Calling Leaderboard, and Mind2Web.
Intended Use
Multimodal Processing: It can process and understand text, images, documents, and video, making it well suited for applications like video captioning, visual question answering, and other multimedia tasks.
Complex Language Tasks: Nova Pro is designed to handle complex language tasks with high accuracy, such as deep reasoning, multi-step problem solving, and mathematical problem-solving.
Agentic Workflows: It powers AI agents capable of performing multi-step tasks, integrated with retrieval-augmented generation (RAG) for improved accuracy and data grounding.
Customizable Applications: Developers can fine-tune it with multimodal data for specific use cases, such as enhancing accuracy, reducing latency, or optimizing cost.
Fast Inference: It’s optimized for fast response times, making it suitable for real-time applications in industries like customer service, automation, and content creation.
Performance
Amazon Nova Pro provides high performance, particularly in complex reasoning, multimodal tasks, and real-time applications, with speed and flexibility for developers.
Limitations
Domain Specialization: While it performs well across a variety of tasks, it may not always be as specialized in certain niche areas or highly specific domains compared to models fine-tuned for those purposes.
Resource-Intensive: As a powerful multimodal model, Nova Pro can require significant computational resources for optimal performance, which might be a consideration for developers working with large datasets or complex tasks.
Training Data: Nova Pro's performance is highly dependent on the quality and diversity of the multimodal data it's trained on. Its performance in tasks involving complex or obscure multimedia content might be less reliable.
Fine-Tuning Requirements: While customizability is a key feature, fine-tuning the model for very specific tasks or datasets might still require considerable effort and expertise from developers.
Citation
Grok
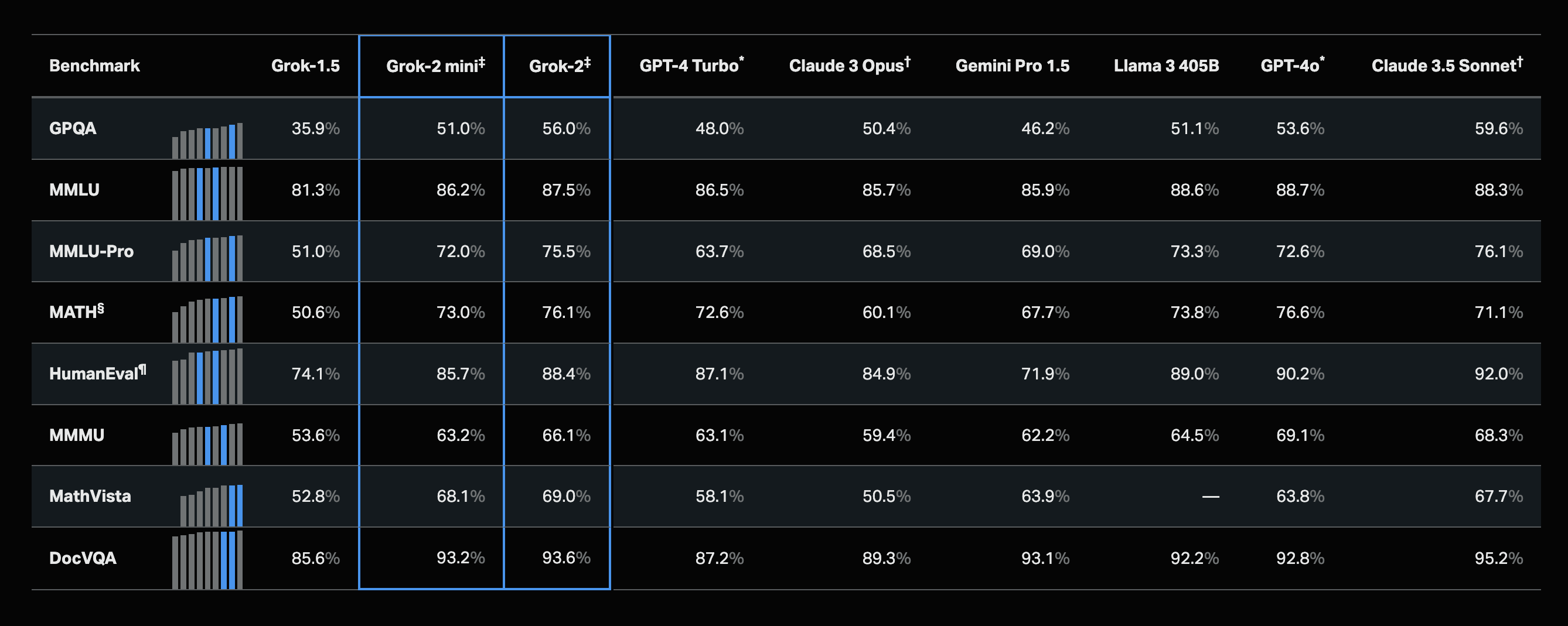
Grok is a general purpose model that can be used for a variety of tasks, including generating and understanding text, code, and function calling.
Intended Use
Text and code: Generate code, extract data, prepare summaries and more.
Vision: Identify objects, analyze visuals, extract text from documents and more.
Function calling: Connect Grok to external tools and services for enriched interactions.
Performance
Limitations
Context: Grok may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As Grok trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Grok may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Grok can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Grok might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the output of Grok are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://x.ai/blog/grok-2
Llama 3.2
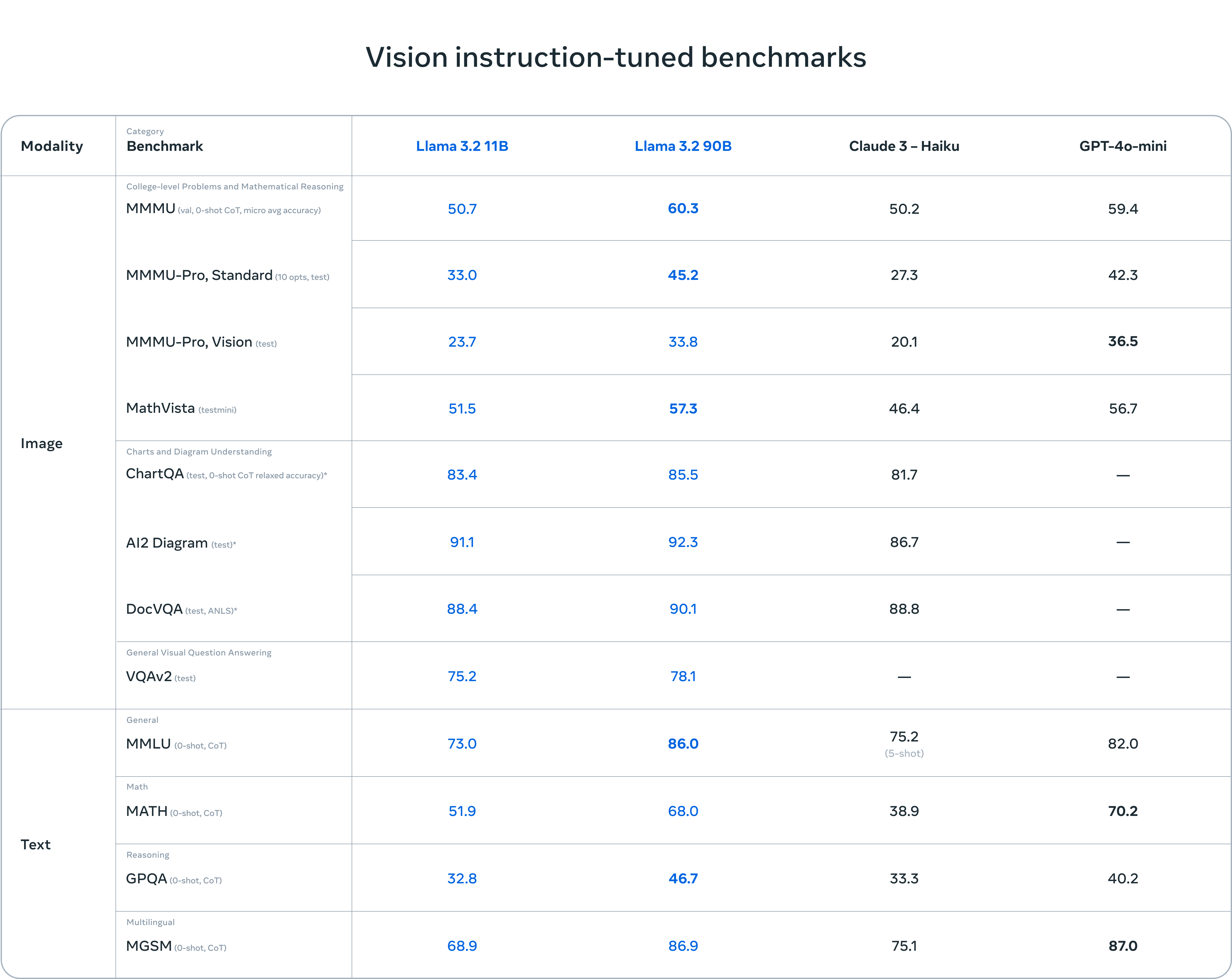
The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of pretrained and instruction-tuned image reasoning generative models in 11B and 90B sizes (text + images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image. The models outperform many of the available open source and closed multimodal models on common industry benchmarks.
Intended Use
Llama 3.2's 11B and 90B models support image reasoning, enabling tasks like understanding charts/graphs, captioning images, and pinpointing objects based on language descriptions. For example, the models can answer questions about sales trends from a graph or trail details from a map. They bridge vision and language by extracting image details, understanding the scene, and generating descriptive captions to tell the story, making them powerful for both visual and textual reasoning tasks.
Llama 3.2's 1B and 3B models support multilingual text generation and on-device applications with strong privacy. Developers can create personalized, agentic apps where data stays local, enabling tasks like summarizing messages, extracting action items, and sending calendar invites for follow-up meetings.
Performance
Llama 3.2 vision models outperform competitors like Gemma 2.6B and Phi 3.5-mini in tasks like image recognition, instruction-following, and summarization.
Limitations
Context: May struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Medical images: Gemini Pro is not suitable for interpreting specialized medical images like CT scans and shouldn't be used for medical advice.
Bias: As it is trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, it may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the output are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
OpenAI GPT-4.1
OpenAI GPT-4.1 is the latest iteration in the GPT series, specifically designed with developers in mind, offering significant advancements in coding, instruction following, and long-context processing. Available exclusively via API, GPT-4.1 aims to enhance the productivity of developers and power more capable AI agents and applications.
Intended Use
Software development (code generation, debugging, testing, code diffs)
Building AI agents and automating complex workflows
Analyzing and processing large documents and codebases (up to 1M tokens)
Tasks requiring precise instruction following and structured outputs
Multimodal applications involving text and image inputs
Performance
GPT-4.1 introduces a massive 1 million token input context window, a substantial increase over previous models, enabling it to process and reason over extremely large texts or datasets in a single prompt. This significantly improves performance on long-context tasks, including document analysis and multi-hop reasoning.
The model demonstrates notable improvements in coding performance, scoring 54.6% on the SWE-Bench Verified benchmark and showing higher accuracy in generating code diffs compared to its predecessors. It is also specifically tuned for better instruction following, showing improved adherence to complex, multi-step directions and reduced misinterpretations on benchmarks like MultiChallenge and IFEval.
GPT-4.1 maintains multimodal capabilities, accepting text and image inputs. It has shown strong performance on multimodal benchmarks, including those involving visual question answering on charts, diagrams, and even extracting information from videos without subtitles. The model is also highlighted for its 100% accuracy on needle-in-a-haystack retrieval across its entire 1M token context window.
Available in a family of models including GPT-4.1, GPT-4.1 mini (optimized for balance of performance and cost), and GPT-4.1 nano (optimized for speed and cost), GPT-4.1 offers flexibility for various developer needs and aims for improved cost-efficiency compared to earlier models like GPT-4o for many use cases.
Limitations
API-only availability: Unlike some previous GPT models, GPT-4.1 is currently available exclusively through the API and is not directly accessible in the ChatGPT consumer interface.
Rate limits: While offering a large context window, practical usage for extremely high-volume or continuous long-context tasks can be impacted by API rate limits, which vary by usage tier.
Reasoning specialization: While demonstrating improved reasoning, GPT-4.1 is not primarily positioned as a dedicated reasoning model in the same category as some models specifically optimized for deep, step-by-step logical deduction.
Potential for "laziness" in smaller variants: Some initial user observations have suggested that the smallest variant, GPT-4.1 nano, can occasionally exhibit a tendency for shorter or less detailed responses, potentially requiring more specific prompting.
Multimodal output: While accepting text and image inputs, the primary output modality is text; it does not generate images directly like some other multimodal models.
Citation
Google Gemini 2.0 Pro
Gemini 2.0 Pro is the strongest model among the family of Gemini models for coding and world knowledge, and it features a 2M long context window. Gemini 2.0 Pro is available as an experimental model in Vertex AI and is an upgrade path for 1.5 Pro users who want better quality, or who are particularly invested in long context and code.
Intended Use
Multimodal input
Text output
Prompt optimizers
Controlled generation
Function calling (excluding compositional function calling)
Grounding with Google Search
Code execution
Count token
Performance
Google Gemini 2.0 Pro boasts the strongest coding performance and superior ability to handle complex prompts, demonstrating better understanding and reasoning of world knowledge than any previous model.
It features the largest context window of 2 million tokens, enabling comprehensive analysis and understanding of large amounts of information. Additionally, it can call external tools like Google Search and execute code, enhancing its utility for a wide range of tasks, including coding and knowledge analysis.
Limitations
Context: Gemini 2.0 Pro may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As Gemini 2.0 Pro is trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Gemini 2.0 Pro may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Gemini 2.0 Pro can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Gemini 2.0 Pro might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of Gemini 2.0 Pro's output are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://cloud.google.com/vertex-ai/generative-ai/docs/gemini-v2#2.0-pro
Claude 3.5 Sonnet
Claude 3.5 Sonnet sets new industry benchmarks for graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (HumanEval). It shows marked improvement in grasping nuance, humor, and complex instructions, and is exceptional at writing high-quality content with a natural, relatable tone. Claude 3.5 Sonnet operates at twice the speed of Claude 3 Opus. This performance boost, combined with cost-effective pricing, makes Claude 3.5 Sonnet ideal for complex tasks such as context-sensitive customer support and orchestrating multi-step workflows.
Intended Use
Task automation: plan and execute complex actions across APIs and databases, interactive coding
R&D: research review, brainstorming and hypothesis generation, drug discovery
Strategy: advanced analysis of charts & graphs, financials and market trends, forecasting
Performance
Advanced Coding ability: In an internal evaluation by Anthropic, Claude 3.5 Sonnet solved 64% of problems, outperforming Claude 3 Opus which solved 38%.
Multilingual Capabilities: Claude 3.5 Sonnet offers improved fluency in non-English languages such as Spanish and Japanese, enabling use cases like translation services and global content creation.
Vision and Image Processing: This model can process and analyze visual input, extracting insights from documents, processing web UI, generating image catalog metadata, and more.
Steerability and Ease of Use: Claude 3.5 Sonnet is designed to be easy to steer and better at following directions, giving you more control over model behavior and more predictable, higher-quality outputs.
Limitations
Here are some of the limitations we are aware of:
Medical images: Claude 3.5 is not suitable for interpreting specialized medical images like CT scans and shouldn't be used for medical advice.
Non-English: Claude 3.5 may not perform optimally when handling images with text of non-Latin alphabets, such as Japanese or Korean.
Big text: Users should enlarge text within the image to improve readability for Claude 3.5, but avoid cropping important details.
Rotation: Claude 3.5 may misinterpret rotated / upside-down text or images.
Visual elements: Claude 3.5 may struggle to understand graphs or text where colors or styles like solid, dashed, or dotted lines vary.
Spatial reasoning: Claude 3.5 struggles with tasks requiring precise spatial localization, such as identifying chess positions.
Hallucinations: the model can provide factually inaccurate information.
Image shape: Claude 3.5 struggles with panoramic and fisheye images.
Metadata and resizing: Claude 3.5 doesn't process original file names or metadata, and images are resized before analysis, affecting their original dimensions.
Counting: Claude 3.5 may give approximate counts for objects in images.
CAPTCHAS: For safety reasons, Claude 3.5 has a system to block the submission of CAPTCHAs.
Citation
Bring your own model
Register your own custom models in Labelbox to pre-label or enrich datasetsLlama 4 Maverick
Meta Llama 4 Maverick is a cutting-edge, natively multimodal AI model from Meta, part of the new Llama 4 family. Built with a Mixture-of-Experts (MoE) architecture, Maverick is designed for advanced text and image understanding, aiming to provide industry-leading performance for a variety of applications at competitive costs.
Intended Use
Developing multimodal assistant applications (image recognition, visual reasoning, captioning, Q&A about images)
Code generation and technical tasks
General-purpose text generation and chat
Enterprise applications requiring multimodal data processing
Research and development in AI
Performance
Llama 4 Maverick features a Mixture-of-Experts architecture with 17 billion active parameters (from a total of 400 billion), contributing to its efficiency and performance. It is natively multimodal, incorporating early fusion of text and image data during training, which allows for seamless understanding and reasoning across modalities. The model supports a context window of up to 1 million tokens, enabling processing of extensive documents and complex inputs.
Benchmark results highlight Maverick's strong capabilities, particularly in multimodal understanding. It has achieved scores of 59.6 on MMLU Pro, 90.0 on ChartQA, 94.4 on DocVQA, 73.4 on MMMU, and 73.7 on MathVista. In coding, it scored 43.4 on LiveCodeBench (specific timeframe). On the LMSYS Chatbot Arena, an experimental chat version of Maverick reportedly achieved an ELO score of 1417, placing it competitively among top models.
Maverick is designed for efficient deployment, capable of running on a single H100 DGX host, with options for distributed inference for larger-scale needs. Its MoE architecture helps balance powerful performance with inference efficiency.
Limitations
EU restriction on vision: Due to regulatory considerations, the use of the vision capabilities for individuals domiciled in, or companies with a principal place of business in, the European Union is not granted under the Llama 4 Community License.
Dedicated reasoning focus: While capable of reasoning, Llama 4 Maverick is not specifically positioned as a dedicated reasoning model in the same vein as some models optimized solely for complex, multi-step logical deduction.
Long context consistency: Despite a large context window, some initial testing has suggested potential for inconsistent performance or degraded results with exceptionally long prompts.
Image input testing: The model has been primarily tested for image understanding with up to 5 input images; performance with a larger number of images may vary, and developers are advised to perform additional testing for such use cases.
Benchmark interpretation: As with many frontier models, there have been discussions regarding the interpretation and representativeness of benchmark scores compared to real-world performance across all possible tasks.
Memory intensity: The Mixture-of-Experts architecture, while efficient for inference, means the full model still requires significant memory to load.
Citation
Information gathered from Meta's official Llama website, announcements, technical documentation (including the Llama 4 Community License), and third-party analyses and benchmark reports.
Google Gemini 2.5 Pro
Gemini 2.5 is a thinking model, designed to tackle increasingly complex problems. Gemini 2.5 Pro Experimental, leads common benchmarks by meaningful margins and showcases strong reasoning and code capabilities. Gemini 2.5 models are thinking models, capable of reasoning through their thoughts before responding, resulting in enhanced performance and improved accuracy.
Intended Use
Multimodal input
Text output
Prompt optimizers
Controlled generation
Function calling (excluding compositional function calling)
Grounding with Google Search
Code execution
Count token
Performance
Google’s latest AI model, Gemini 2.5 Pro, represents a major leap in AI performance and reasoning capabilities. Positioned as the most advanced iteration in the Gemini lineup, this experimental release of 2.5 Pro is now the top performer on the LMArena leaderboard, surpassing other models by a notable margin in human preference evaluations.
Gemini 2.5 builds on Google’s prior efforts to enhance reasoning in AI, incorporating advanced techniques like reinforcement learning and chain-of-thought prompting. This version introduces a significantly upgraded base model paired with improved post-training, resulting in better contextual understanding and more accurate decision-making. The model is designed as a “thinking model,” capable of deeply analyzing information before responding — a capability now embedded across all future Gemini models.
The reasoning performance of 2.5 Pro stands out across key benchmarks such as GPQA and AIME 2025, even without cost-increasing test-time techniques. It also achieved a state-of-the-art 18.8% score on “Humanity’s Last Exam,” a benchmark crafted by experts to evaluate deep reasoning across disciplines.
In terms of coding, Gemini 2.5 Pro significantly outperforms its predecessors. It excels in creating complex, visually rich web apps and agentic applications. On SWE-Bench Verified, a standard for evaluating coding agents, the model scored an impressive 63.8% using a custom setup.
Additional features include a 1 million token context window, with plans to extend to 2 million, enabling the model to manage vast datasets and multimodal inputs — including text, images, audio, video, and code repositories.
Limitations
Context: Google Gemini 2.5 Pro may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As it is trained on a large corpus of internet text, Google Gemini 2.5 Pro may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Google Gemini 2.5 Pro may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Google Gemini 2.5 Pro can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Google Gemini 2.5 Pro might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the model’s output are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://cloud.google.com/vertex-ai/generative-ai/docs/gemini-v2#2.5-pro
Grok 3
Grok 3, developed by xAI, is positioned as a highly advanced AI model engineered for complex problem-solving and real-time information processing. Leveraging a massive computational infrastructure, Grok 3 introduces innovative features like "Think mode" for detailed reasoning and "DeepSearch" for integrating current web data, aiming to push the boundaries of AI capabilities across various domains.
Intended Use
Real-time data analysis and research
Code generation and debugging
Educational assistance and STEM learning
Business process automation
Generating both conversational and detailed responses
Performance
Powered by the Colossus supercomputer with over 200,000 NVIDIA H100 GPUs, Grok 3 represents a significant leap in computational power, reportedly 10-15x more powerful than its predecessor. This enables enhanced speed and efficiency in processing complex queries. Grok 3 has demonstrated impressive results across key benchmarks.
It achieved a 93.3% score on the AIME 2025 mathematical assessment and 84.6% on graduate-level expert reasoning tasks (GPQA). In coding challenges, it scored 79.4% on LiveCodeBench. Internal benchmarks from xAI also suggest Grok 3 outperforms several leading models, including Gemini 2.5 Pro, GPT-4o, and Claude 3.5 Sonnet, in specific reasoning, math, and coding tasks.
A notable feature is "Think mode," which allows Grok 3 to break down problems and show its step-by-step reasoning process, similar to human structured thinking. "Big Brain mode" allocates additional computational resources for demanding tasks, delivering higher accuracy and deeper insights. The "DeepSearch" capability allows the model to pull and synthesize real-time information from the web, addressing the limitation of relying solely on static training data.
While benchmark performance is strong, real-world performance comparisons show varied results, with Grok 3 excelling in logic-heavy tasks and real-time data integration.
Limitations
Content coherency: Grok 3 may struggle with maintaining full coherency in generating very long-form content (e.g., beyond 5-10 pages).
Real-time data reliability: While "DeepSearch" provides access to real-time data from sources like X and the web, there is a potential risk of generating unverified or biased information depending on the source quality.
Varied real-world performance: Despite strong benchmark scores, some early real-world tests indicate that Grok 3 may not consistently outperform all rival models in every specific task.
Creativity nuances: The model's creative writing abilities may be perceived as more functional than nuanced compared to models specifically fine-tuned for highly creative tasks.
Resource intensity: Utilizing advanced reasoning modes like "Big Brain" requires significant computational resources, which could impact response times and cost efficiency depending on the application.
Citation
Information gathered from various public sources, including xAI announcements, technical reviews, and public benchmark analyses.
OpenAI o4-mini
OpenAI o4-mini is a recent addition to OpenAI's 'o' series of models, designed to provide fast, cost-efficient, and capable reasoning for a wide range of tasks. It balances performance with efficiency, making advanced AI reasoning more accessible for various applications, including those requiring high throughput.
Intended Use
Fast technical tasks (data extraction, summarization of technical content)
Coding assistance (fixing issues, generating code)
Automating workflows (intelligent email triage, data categorization)
Processing and reasoning about multimodal inputs (text and images)
Applications where speed and cost-efficiency are key
Performance
OpenAI o4-mini is optimized for speed and affordability while still demonstrating strong reasoning capabilities. It features a substantial 200,000-token context window, allowing it to handle lengthy inputs and maintain context over extended interactions. The model supports up to 100,000 output tokens.
Despite being a smaller model, o4-mini shows competitive performance on several benchmarks, particularly in STEM and multimodal reasoning tasks. It has achieved scores such as 93.4% on AIME 2024 and 81.4% on GPQA (without tools). In coding, it demonstrates effective performance on benchmarks like SWE-Bench.
A key capability of o4-mini is its integration with OpenAI's suite of tools, including web Browse, Python code execution, and image analysis. The model is trained to intelligently decide when and how to use these tools to solve complex problems and provide detailed, well-structured responses, even incorporating visual information into its reasoning process. This makes it adept at tasks that require combining information from multiple sources or modalities.
Compared to larger models like OpenAI o3, o4-mini generally offers faster response times and significantly lower costs per token, making it a strong candidate for high-volume or latency-sensitive applications.
Limitations
Usage limits: Access to o4-mini on ChatGPT is subject to usage limits depending on the subscription tier (Free, Plus, Team, Enterprise/Edu).
Fine-tuning: As of the latest information, fine-tuning capabilities are not yet available for o4-mini.
Reasoning depth: While strong for its size, o4-mini may not offer the same depth of reasoning as larger, more powerful models like o3 for the most complex, multi-step problems.
Benchmark vs. real-world: As with any model, performance on specific benchmarks may not always perfectly reflect performance on all real-world, highly-nuanced tasks.
Citation
Information gathered from OpenAI's official announcements, documentation, and third-party analyses of model capabilities and benchmarks.
Bring your own model
Register your own custom models in Labelbox to pre-label or enrich datasetsOpen AI Whisper
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual data, offering improved robustness to accents, noise, and technical language. It transcribes and translates multiple languages into English.
Intended Use
Whisper is useful as an ASR solution, especially for English speech recognition.
The models are primarily trained and evaluated on ASR and speech translation to English.
They show strong ASR results in about 10 languages.
They may exhibit additional capabilities if fine-tuned for tasks like voice activity detection, speaker classification, or speaker diarization.
Performance
Speech recognition and translation accuracy is near state-of-the-art.
Performance varies across languages, with lower accuracy on low-resource or low-discoverability languages.
Whisper shows varying performance on different accents and dialects of languages.
Limitations
Whisper is trained in a weakly supervised manner using large-scale noisy data, leading to potential hallucinations.
Hallucinations occur as the models combine predicting the next word and transcribing audio.
The sequence-to-sequence architecture may generate repetitive text, which can be partially mitigated by beam search and temperature scheduling.
These issues may be more pronounced in lower-resource and/or lower-discoverability languages.
Higher word error rates may occur across speakers of different genders, races, ages, or other demographics.
Citation
https://openai.com/index/whisper/
Open AI o3 mini
OpenAI o3-mini is a powerful and fast model that advances the boundaries of what small models can achieve. It delivers, exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of OpenAI o1-mini.
Intended Use
OpenAI o3-mini is designed to be used for tasks that require fast and efficient reasoning, particularly in technical domains like science, math, and coding. It’s optimized for STEM (Science, Technology, Engineering, and Mathematics) problem-solving, offering precise answers with improved speed compared to previous models.
Developers can use it for applications involving function calling, structured outputs, and other technical features. It’s particularly useful in contexts where both speed and accuracy are essential, such as coding, logical problem-solving, and complex technical inquiries.
Performance
OpenAI o3-mini performs exceptionally well in STEM tasks, particularly in science, math, and coding, with improvements in both speed and accuracy compared to its predecessor, o1-mini. It delivers faster responses, with an average response time 24% quicker than o1-mini (7.7 seconds vs. 10.16 seconds).
In terms of accuracy, it produces clearer, more accurate answers, with 39% fewer major errors on complex real-world questions. Expert testers preferred its responses 56% of the time over o1-mini. It also matches o1-mini’s performance in challenging reasoning evaluations, including AIME and GPQA, especially when using medium reasoning effort.
Limitations
No Vision Capabilities: Unlike some other models, o3-mini does not support visual reasoning tasks, so it's not suitable for image-related tasks.
Complexity in High-Intelligence Tasks: While o3-mini performs well in most STEM tasks, for extremely complex reasoning, it may still lag behind larger models.
Accuracy in Specific Domains: While o3-mini excels in technical domains, it might not always match the performance of specialized models in certain niche areas, particularly those outside of STEM.
Potential Trade-Off Between Speed and Accuracy: While users can adjust reasoning effort for a balance, higher reasoning efforts may lead to slightly longer response times.
Limited Fine-Tuning: Though optimized for general STEM tasks, fine-tuning for specific use cases might be necessary to achieve optimal results in more specialized areas.
Citation
https://openai.com/index/openai-o3-mini/
Claude 3.7 Sonnet
Claude 3.7 Sonnet, by Anthropic, can produce near-instant responses or extended, step-by-step thinking. Claude 3.7 Sonnet shows particularly strong improvements in coding and front-end web development.
Intended Use
Claude 3.7 Sonnet is designed to enhance real-world tasks by offering a blend of fast responses and deep reasoning, particularly in coding, web development, problem-solving, and instruction-following.
Optimized for real-world applications rather than competitive math or computer science problems.
Useful in business environments requiring a balance of speed and accuracy.
Ideal for tasks like bug fixing, feature development, and large-scale refactoring.
Coding Capabilities:
Strong in handling complex codebases, planning code changes, and full-stack updates.
Introduces Claude Code, an agentic coding tool that can edit files, write and run tests, and manage code repositories like GitHub.
Claude Code significantly reduces development time by automating tasks that would typically take 45+ minutes manually.
Performance
Claude Sonnet 3.7 combines the capabilities of a language model (LLM) with advanced reasoning, allowing users to choose between standard mode for quick responses and extended thinking mode for deeper reflection before answering. In extended thinking mode, Claude self-reflects, improving performance in tasks like math, physics, coding, and following instructions. Users can also control the thinking time via the API, adjusting the token budget to balance speed and answer quality.
Early testing demonstrated Claude’s superiority in coding, with significant improvements in handling complex codebases, advanced tool usage, and planning code changes. It also excels at full-stack updates and producing production-ready code with high precision, as seen in use cases with platforms like Vercel, Replit, and Canva. Claude's performance is particularly strong in developing sophisticated web apps, dashboards, and reducing errors. This makes it a top choice for developers working on real-world coding tasks.
Limitations
Context: Claude 3.7 Sonnet may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As Claude 3.7 Sonnet trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Claude 3.7 Sonnet may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Claude 3.7 Sonnet can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Claude 3.7 Sonnet might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the output of Claude 3.7 Sonnet are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://www.anthropic.com/news/claude-3-7-sonnet
Amazon Nova Pro
Amazon Nova Pro is a highly capable multimodal model that combines accuracy, speed, and cost for a wide range of tasks.
The capabilities of Amazon Nova Pro, coupled with its focus on high speeds and cost efficiency, makes it a compelling model for almost any task, including video summarization, Q&A, mathematical reasoning, software development, and AI agents that can execute multistep workflows.
In addition to state-of-the-art accuracy on text and visual intelligence benchmarks, Amazon Nova Pro excels at instruction following and agentic workflows as measured by Comprehensive RAG Benchmark (CRAG), the Berkeley Function Calling Leaderboard, and Mind2Web.
Intended Use
Multimodal Processing: It can process and understand text, images, documents, and video, making it well suited for applications like video captioning, visual question answering, and other multimedia tasks.
Complex Language Tasks: Nova Pro is designed to handle complex language tasks with high accuracy, such as deep reasoning, multi-step problem solving, and mathematical problem-solving.
Agentic Workflows: It powers AI agents capable of performing multi-step tasks, integrated with retrieval-augmented generation (RAG) for improved accuracy and data grounding.
Customizable Applications: Developers can fine-tune it with multimodal data for specific use cases, such as enhancing accuracy, reducing latency, or optimizing cost.
Fast Inference: It’s optimized for fast response times, making it suitable for real-time applications in industries like customer service, automation, and content creation.
Performance
Amazon Nova Pro provides high performance, particularly in complex reasoning, multimodal tasks, and real-time applications, with speed and flexibility for developers.
Limitations
Domain Specialization: While it performs well across a variety of tasks, it may not always be as specialized in certain niche areas or highly specific domains compared to models fine-tuned for those purposes.
Resource-Intensive: As a powerful multimodal model, Nova Pro can require significant computational resources for optimal performance, which might be a consideration for developers working with large datasets or complex tasks.
Training Data: Nova Pro's performance is highly dependent on the quality and diversity of the multimodal data it's trained on. Its performance in tasks involving complex or obscure multimedia content might be less reliable.
Fine-Tuning Requirements: While customizability is a key feature, fine-tuning the model for very specific tasks or datasets might still require considerable effort and expertise from developers.
Citation
Grok
Grok is a general purpose model that can be used for a variety of tasks, including generating and understanding text, code, and function calling.
Intended Use
Text and code: Generate code, extract data, prepare summaries and more.
Vision: Identify objects, analyze visuals, extract text from documents and more.
Function calling: Connect Grok to external tools and services for enriched interactions.
Performance
Limitations
Context: Grok may struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Bias: As Grok trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, Grok may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Grok can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Grok might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the output of Grok are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://x.ai/blog/grok-2
Llama 3.2
The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of pretrained and instruction-tuned image reasoning generative models in 11B and 90B sizes (text + images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image. The models outperform many of the available open source and closed multimodal models on common industry benchmarks.
Intended Use
Llama 3.2's 11B and 90B models support image reasoning, enabling tasks like understanding charts/graphs, captioning images, and pinpointing objects based on language descriptions. For example, the models can answer questions about sales trends from a graph or trail details from a map. They bridge vision and language by extracting image details, understanding the scene, and generating descriptive captions to tell the story, making them powerful for both visual and textual reasoning tasks.
Llama 3.2's 1B and 3B models support multilingual text generation and on-device applications with strong privacy. Developers can create personalized, agentic apps where data stays local, enabling tasks like summarizing messages, extracting action items, and sending calendar invites for follow-up meetings.
Performance
Llama 3.2 vision models outperform competitors like Gemma 2.6B and Phi 3.5-mini in tasks like image recognition, instruction-following, and summarization.
Limitations
Context: May struggle with maintaining context over extended conversations, leading to inconsistencies in long interactions.
Medical images: Gemini Pro is not suitable for interpreting specialized medical images like CT scans and shouldn't be used for medical advice.
Bias: As it is trained on a large corpus of internet text, it may inadvertently reflect and perpetuate biases present in the training data.
Creativity Boundaries: While capable of creative outputs, it may not always meet specific creative standards or expectations for novel and nuanced content.
Ethical Concerns: Can be used to generate misleading information, offensive content, or be exploited for harmful purposes if not properly moderated.
Comprehension: Might not fully understand or accurately interpret highly technical or domain-specific content, especially if it involves recent developments post-training data cutoff.
Dependence on Prompt Quality: The quality and relevance of the output are highly dependent on the clarity and specificity of the input prompts provided by the user.
Citation
https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/







Let foundation models do the work
We are bringing together the world's best AI models to help you perform data labeling and enrichment tasks across all supported data modalities. Achieve breakthroughs in data generation speed and costs. Re-focus human efforts on quality assurance.

"We love our initial use of Model Foundry. Instead of going into unstructured text datasets blindly, we can now use pre-existing LLMs to pre-label data or pre-tag parts of it. Model Foundry serves as a co-pilot for training data."
- Alexander Booth, Assistant Director of the World Series Champions, Texas Rangers
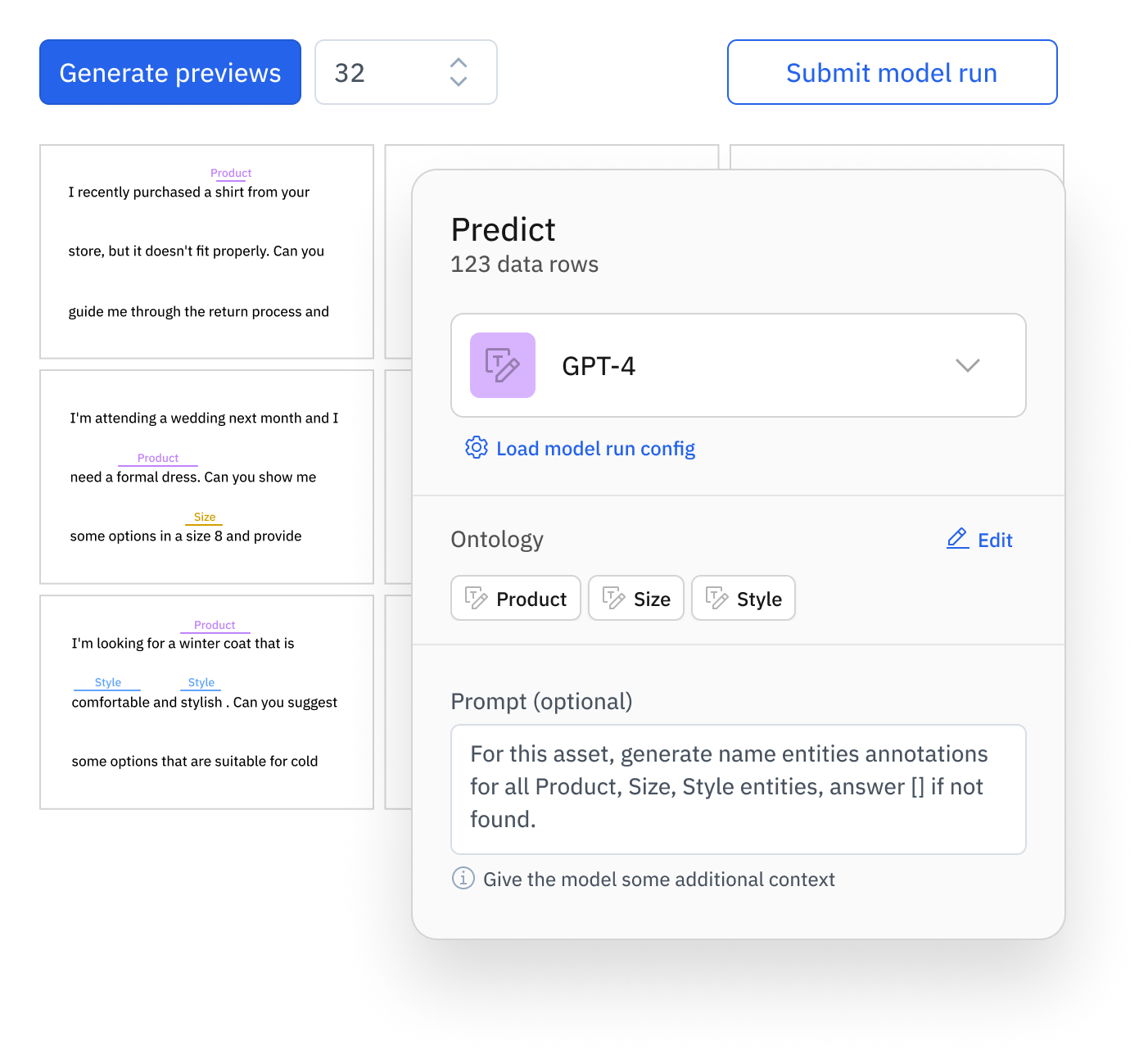
Pre-label data in a few clicks
AI builders can now enrich datasets and pre-label data in minutes without code using foundation models offered by leading providers or open source alternatives. Model-assisted labeling using Foundry accelerates data labeling tasks on images, text, and documents at a fraction of the typical cost and speed.
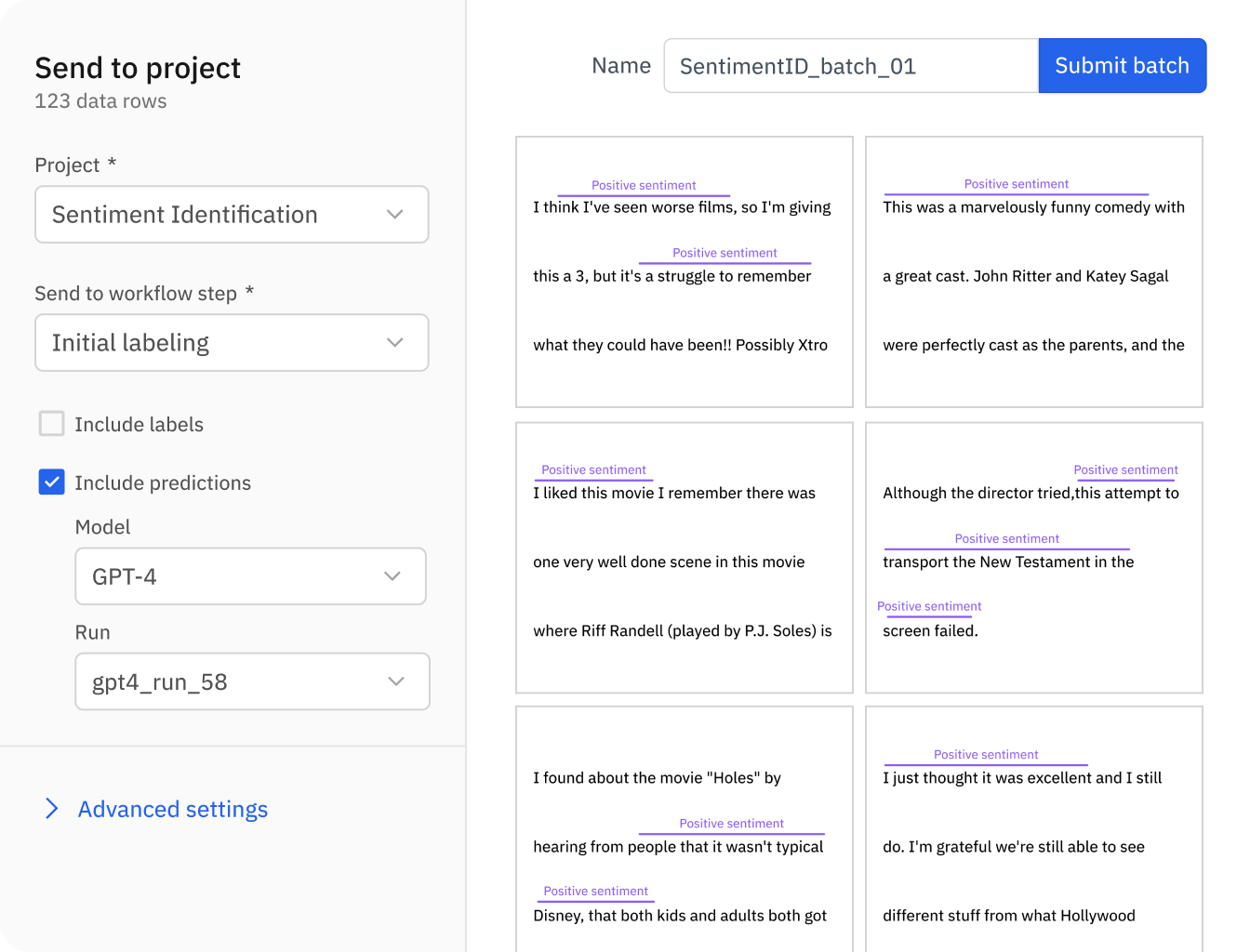
Focus human expertise on where it matters most
The days of manually labeling from scratch are long gone. Foundation models can outperform crowd-sourced labeling on various tasks with high accuracy – allowing you to focus valuable human efforts on critical review. Combine model-assisted labeling using foundation models with human-in-the-loop review to accelerate your labeling operations and build intelligent AI faster than ever.
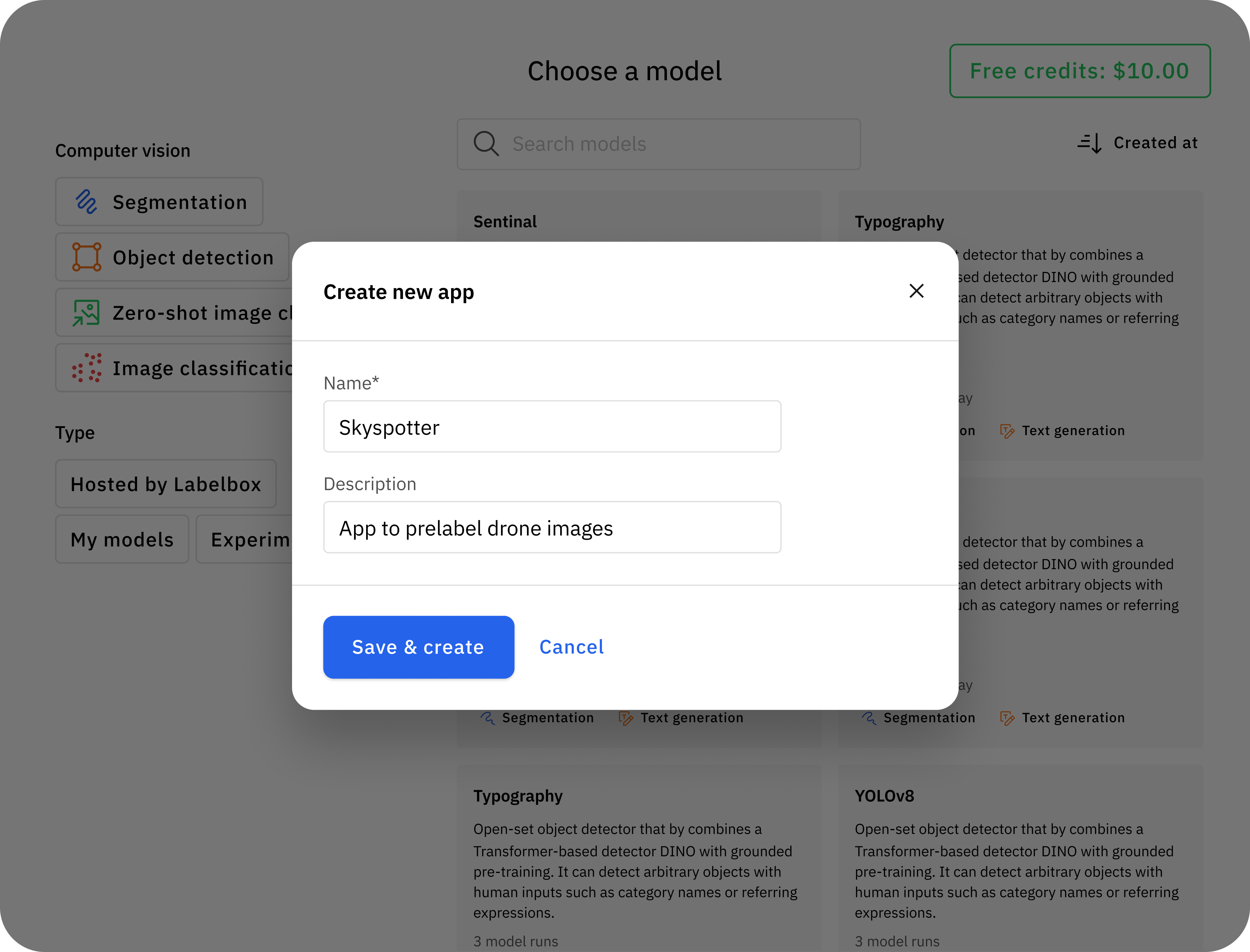
Automate data tasks with Foundry Apps
Create custom Apps with Foundry based on your team’s needs. Deploy a model configuration from Foundry to an App for automated data management or to build custom intelligent applications.
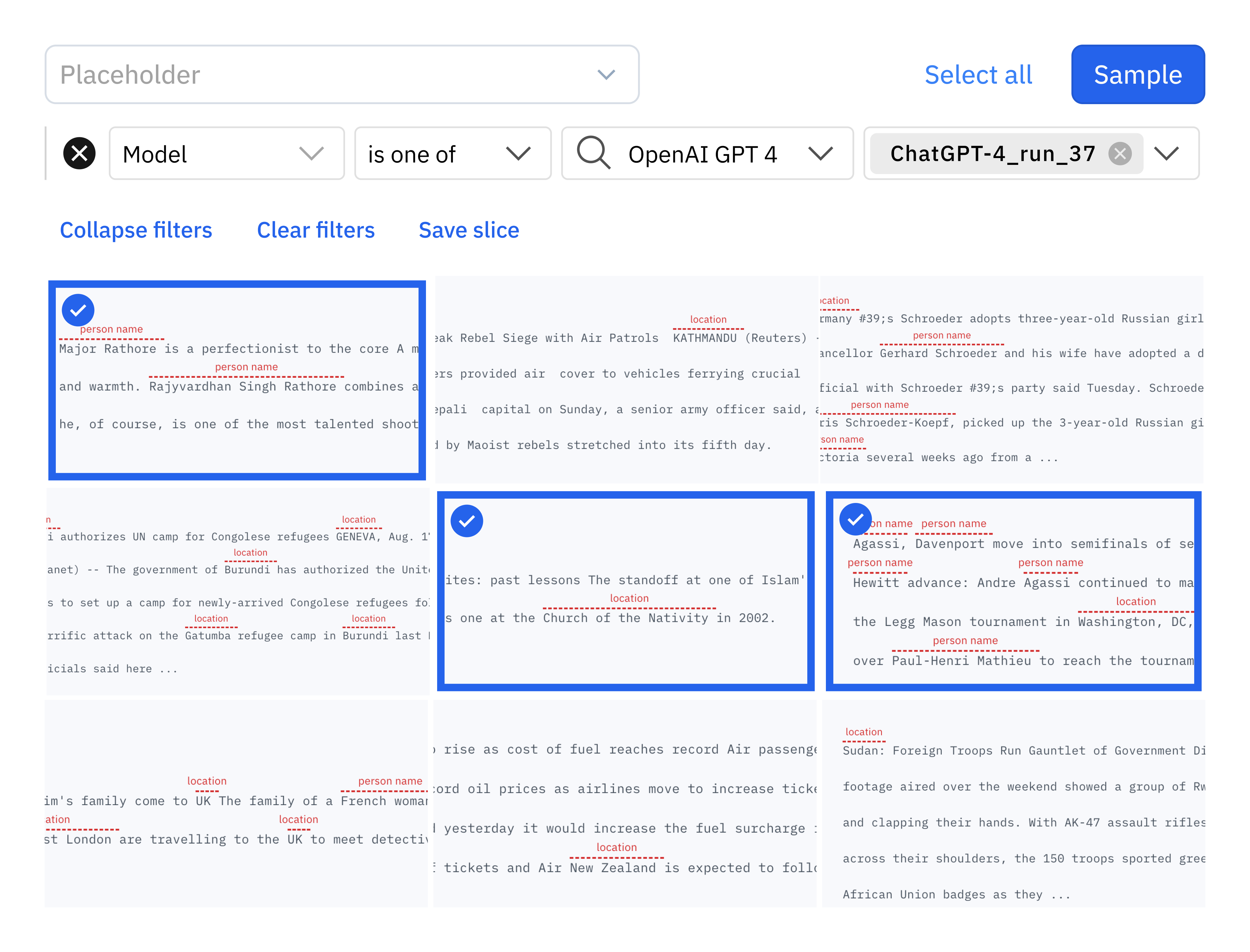
Explore datasets using AI insights
Curate and explore datasets faster than ever. Query your data using predictions generated from the latest and greatest foundation models. Supercharge your data enrichment process and accelerate curation efforts across image and text data modalities.

Accelerate custom model development
Data enriched by Foundry can be used to tailor foundation models to your specific use cases:
Fine-tune leading foundation models: Optimize foundation models for your most valuable AI use cases. Enhance performance for specialized tasks in just days instead of months.
Distill knowledge into smaller models: Elaborate foundation models into lightweight models purpose-built for your applications.
Frequently asked questions
Who gets access to the Model Foundry?
To use Labelbox Foundry, you will need to be a part of our Starter or Enterprise plans. You will be billed monthly for the pass-through compute costs associated with foundation models run on your data in Labelbox.
Learn more about how to upgrade to a pay-as-you-go Starter plan or about our Labelbox Unit pricing.
Contact us to receive more detailed instructions on how to create a Labelbox Starter or Enterprise account or upgrade to our Starter tier.
How is Foundry priced?
Only pay for the models that you want to pre-label or enrich your data with. Foundry pricing will be calculated and billed monthly based on the following:
Inference cost – Labelbox will charge customers for inference costs for all models hosted by Labelbox. Inference costs will be bespoke to each model available in Foundry. The inference price is determined based on vendors or our compute costs – these are published publicly on our website as well as inside the product.
Labelbox's platform cost – each asset with predictions generated by Foundry will accrue LBUs.
Learn more about the pricing of the Foundry add-on for Labelbox Model on our pricing page.
What kind of foundation models are available?
Labelbox Foundry currently supports a variety of tasks for computer vision and natural language processing. This includes powerful open-source and third-party models across text generation, object detection, translation, text classification, image segmentation, and more. For a full list of available models, please visit this page.
How do I get started with Foundry?
If you aren’t currently a Labelbox user or are on our Free plan, you’ll need to:
Create a Labelbox account
Upgrade your account to our Starter plan:
In the Billing tab, locate “Starter” in the All Plans list and select “Switch to Plan.” The credit card on file will only be charged when you exceed your existing free 10,000 LBU.
Upgrades take effect immediately so you'll have access to Foundry right away on the Starter plan. After upgrading, you’ll see the option to activate Foundry for your organization.
Follow the steps below on how to get started generating model predictions with Foundry.
If you are currently a Labelbox customer on our Starter or Enterprise plans, you automatically have the ability to opt-in to using Foundry:
After selecting data in Catalog and hitting “Predict with Foundry,” you’ll be able to select a foundation model and submit a model run to generate predictions. You can learn more about the Foundry workflow and see it in-action in this guide.
When submitting a model run, you’ll see the option to activate Foundry for your organization’s Admins. You’ll need to agree to Labelbox’s Model Foundry add-on service terms and confirm you understand the associated compute fees.
Does Labelbox sell or use customer data via Foundry?
Labelbox does not sell or use customer data in a way other than to provide you the services.
Do the third-party model providers use customer data to train their models?
Labelbox's third-party model providers will not use your data to train their models, as governed by specific 'opt-out' terms between Labelbox and our third-party model providers.
Can I use the closed source models available through Foundry for pre-labeling?
OpenAI: Labelbox believes that you have the right to use OpenAI’s closed-source models (e.g, GPT-4, GPT3.5, etc) for pre-labeling through Foundry if you comply with applicable laws and otherwise follow OpenAI’s usage policies. If you wish to use your own instance of OpenAI, you can do so by setting up a custom model on Foundry.
Anthropic: Labelbox believes that you have the right to use Anthropic’s Claude for pre-labeling through Foundry if you comply with applicable laws and otherwise follow Anthropic’s Acceptable Use Policy. If you wish to use your own instance of Anthropic, you can do so by setting up a custom model on Foundry.
Google: Labelbox believes that you have the right to use Google’s Gemini (or other closed-source models such as Imagen, PalLM, etc.) for pre-labeling through Foundry if you comply with applicable laws and otherwise follow the Gemini API Additional Terms of Service, including without limitation the Generative AI Prohibited Use Policy. If you wish to use your own instance of Google, you can do so by setting up a custom model on Foundry.

